
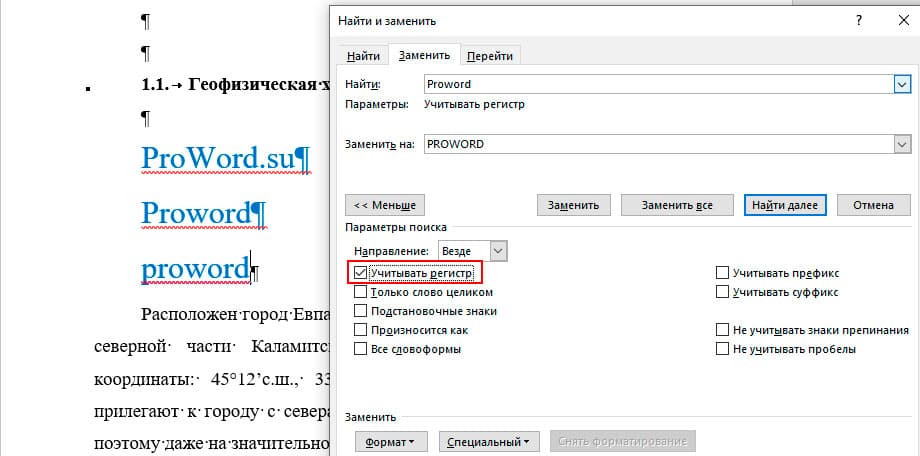
Особенности без учета регистра в поисковых системах
Без учета регистра — это особенность поисковых систем, при которой они не различают прописные и заглавные буквы при поиске информации. Это означает, что при выполнении поискового запроса «ключевое слово», поисковая система выдаст результаты, где ключевое слово может быть написано как заглавными буквами, так и прописными.
Эта особенность облегчает поиск информации для пользователей, так как они могут вводить запросы без необходимости следить за регистром букв. Однако при этом возникают некоторые нюансы, которые следует учитывать.
Во-первых, при определенных запросах поисковая система может выдать результаты, которые отличаются в зависимости от регистра. Например, запрос «apple» может выдать результаты о фрукте, а запрос «Apple» может выдать результаты о компании Apple. Пользователям следует быть внимательными при поиске информации и, при необходимости, указывать желаемый регистр в запросе.
Во-вторых, без учета регистра может быть сложнее различать существительные от прилагательных или глаголов. Например, запрос «новая игра» может быть интерпретирован как «новая игра» или «новая игра» в зависимости от контекста, что может привести к нежелательным результатам.
Для того чтобы получить более точные результаты при поиске в поисковых системах, рекомендуется использовать кавычки. Например, запрос «Новая игра» будет искать именно эту фразу, а не отдельные слова «новая» и «игра».
Таким образом, особенность без учета регистра в поисковых системах упрощает поиск информации для пользователей, но требует внимательности и правильного формулирования запросов для получения наиболее релевантных результатов.
Как применить без учета регистра в своей деятельности?
В своей деятельности вы можете применять без учета регистра, используя следующие методы:
- Поиск и фильтрация: Если вы работаете с большими объемами текстовых данных, вы можете применять без учета регистра при поиске и фильтрации информации. Это позволит вам находить и выбирать данные, игнорируя различия в регистре. Например, при поиске имени пользователя в базе данных или при фильтрации списка товаров.
- Сравнение текстов: При сравнении текстовых значений вы можете использовать без учета регистра, чтобы проверить, совпадают ли они. Это особенно полезно при проверке паролей, вводимых пользователями, или при сравнении входных данных с предопределенными значениями.
- Обработка команд: Если вы разрабатываете программу или интерфейс, вы можете обеспечить без учета регистра при обработке команд от пользователя. Например, вы можете разрешить пользователю вводить команды как в верхнем, так и в нижнем регистре, и обрабатывать их одинаково.
Применение без учета регистра может значительно упростить вашу работу с текстовыми данными и повысить удобство использования вашего продукта или сервиса. Учтите, однако, что в некоторых случаях различие в регистре может быть важным, поэтому не забывайте адаптировать свои методы под конкретные требования и контекст вашей деятельности.
В области программирования
В области программирования без учета регистра относится к функциональности, которая игнорирует различия между заглавными и строчными буквами при обработке текста или символов. Это означает, что при сравнении строк или символов, регистр не учитывается, и символы, написанные заглавными или строчными буквами, считаются одинаковыми.
В программировании без учета регистра может быть полезным во многих сценариях. Например, в поисковых системах, при поиске по тексту, без учета регистра можно делать запросы без различия между заглавными и строчными буквами. Это обеспечивает большую гибкость и удобство для пользователей при поиске.
Также без учета регистра может быть полезным при сравнении строк, особенно при проверке идентификаторов или паролей. Это позволяет упростить код и сделать его менее подверженным ошибкам, связанным с регистром символов.
В языке программирования, поддерживающем без учета регистра, существуют специальные функции или методы, которые позволяют выполнить операции без учета регистра. Например, в языке JavaScript методы toLowerCase() и toUpperCase() могут использоваться для приведения строки к нижнему или верхнему регистру соответственно.
В целом, применение без учета регистра в программировании повышает удобство и гибкость, упрощает разработку и уменьшает вероятность ошибок, связанных с регистром символов. Этот подход широко используется в различных областях программирования и языках программирования для улучшения пользовательского опыта и облегчения обработки текста и символов.
В работе с документами
При создании и редактировании документов может возникнуть необходимость игнорирования регистра символов. Понятие «без учета регистра» означает, что вся информация, включая буквы в верхнем и нижнем регистре, считается одинаковой и не влияет на результаты поиска, сортировки или фильтрации.
Без учета регистра особенно полезен при работе с текстовыми документами, где может быть необходимость найти определенное слово или фразу, независимо от того, в какой форме оно записано. Например, если ищется слово «apple», то без учета регистра также будут найдены слова «APPLE», «AppLE» и т.д.
Применение без учета регистра в работе с документами позволяет значительно упростить поиск и обработку информации. Эта функция может быть реализована в текстовых редакторах, поисковых системах, базах данных и многих других программных средствах.
За счет игнорирования регистра символов, пользователи могут быстро находить необходимую информацию, не задумываясь о том, как она записана. Это позволяет улучшить производительность и эффективность работы с документами, особенно при работе с большим объемом данных.
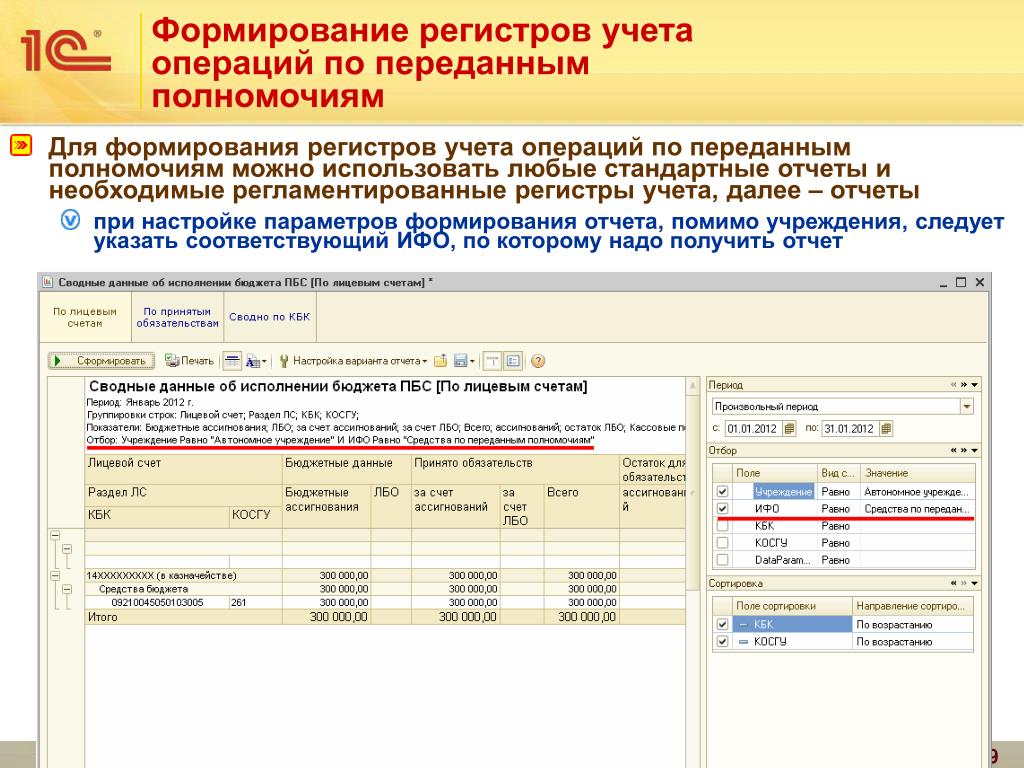
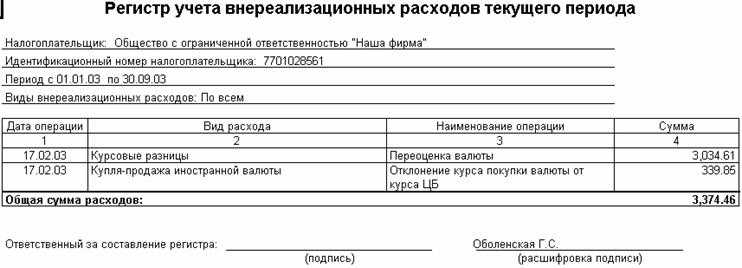
ИНДЕКС+ПОИСКПОЗ – поиск с учётом регистра для любых типов данных
Наконец мы приблизились к неограниченной по возможностям и чувствительной к регистру формуле поиска, которая работает с любыми наборами данных.
Этот пример идёт последним не потому, что лучшее оставлено на десерт, а потому, что знания, полученные из предыдущих примеров, помогут лучше и быстрее понять чувствительную к регистру формулу ИНДЕКС+ПОИСКПОЗ (INDEX+MATCH).
Как Вы, наверное, догадались, комбинация функций ПОИСКПОЗ и ИНДЕКС используется в Excel как более гибкая и мощная альтернатива для ВПР. Статья Использование ИНДЕКС и ПОИСКПОЗ вместо ВПР прекрасно объяснит Вам, как эти функции работают в паре.
Я лишь напомню ключевые моменты:
- Функция ПОИСКПОЗ (MATCH) ищет значение в заданном диапазоне и возвращает его относительную позицию, то есть номер строки и/или столбца;
- Далее, функция ИНДЕКС (INDEX) возвращает значение из определённого столбца и/или строки.
Чтобы формула ИНДЕКС+ПОИСКПОЗ могла искать с учётом регистра, к ней нужно добавить лишь одну функцию. Не трудно догадаться, что это снова СОВПАД (EXACT):
В этой формуле СОВПАД работает так же, как и в , и даёт такой же результат:
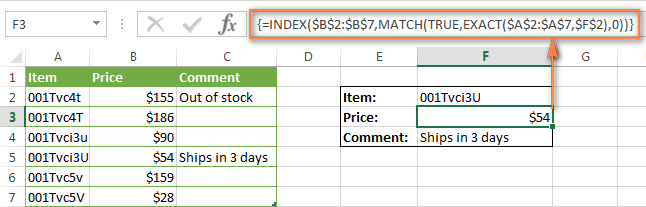
Заметьте, что формула ИНДЕКС+ПОИСКПОЗ заключена в фигурные скобки – это формула массива, и Вы должны завершить её ввод нажатием Ctrl+Shift+Enter.
Почему ИНДЕКС+ПОИСКПОЗ – это лучшее решение для поиска с учётом регистра?
Главные преимущества связки ИНДЕКС и ПОИСКПОЗ:
- Не требует добавления вспомогательного столбца, в отличие от ВПР.
- Не требует сортировки столбца поиска, в отличие от ПРОСМОТР.
- Работает со всеми типами данных – с числами, текстом и датами.
Эта формула кажется идеальной, не правда ли? На самом деле, это не так. И вот почему.
Предположим, что ячейка в столбце возвращаемых значений, связанных с искомым значением, пуста. Какой результат возвратит формула? Никакой? Давайте посмотрим, что возвратит формула на самом деле:
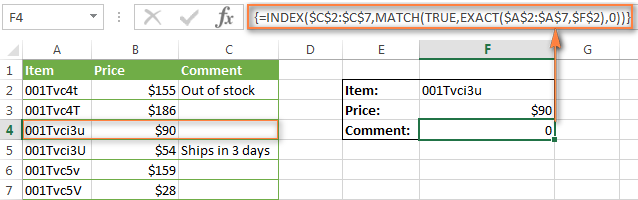
Упс, формула возвращает ноль! Это может быть не велика беда, если Вы работаете с чисто текстовыми значениями. Однако, если таблица содержит числа, в том числе «настоящие» нули – это становится проблемой.
На самом деле, все остальные формулы поиска (ВПР, ПРОСМОТР и СУММПРОИЗВ), которые мы обсуждали ранее, ведут себя так же. Но Вы же хотите безупречную формулу, так ведь?
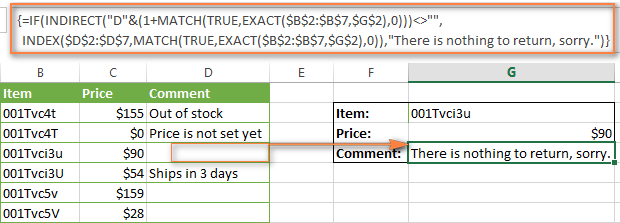
Чтобы сделать чувствительную к регистру формулу ИНДЕКС+ПОИСКПОЗ идеальной, поместите её в функцию ЕСЛИ (IF), которая будет проверять ячейку с возвращаемым значением и возвращать пустой результат, если она пуста:
В этой формуле:
- B – это столбец с возвращаемыми значениями
- 1+ – это число, которое превращает относительную позицию ячейки, возвращаемую функцией ПОИСКПОЗ, в реальный адрес ячейки. Например, в нашей функции ПОИСКПОЗ задан массив поиска A2:A7, то есть относительная позиция ячейки A2 будет 1, потому что она первая в массиве. Но реальная позиция ячейки A2 в столбце – это 2, поэтому мы добавляем 1, чтобы компенсировать разницу и чтобы функция ДВССЫЛ (INDIRECT) извлекла значение из нужной ячейки.
Рисунки ниже демонстрируют исправленную чувствительную к регистру формулу ИНДЕКС+ПОИСКПОЗ в действии. Она возвращает пустой результат, если возвращаемая ячейка пуста.
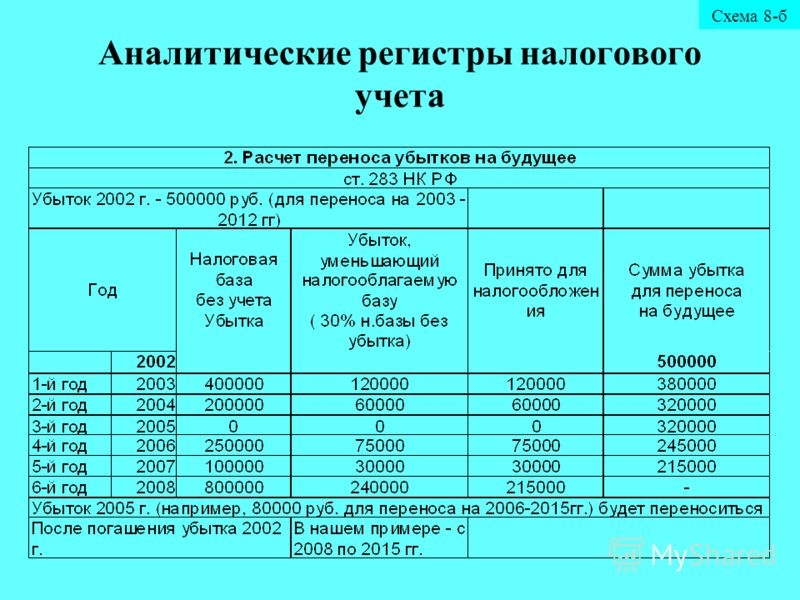



Я переписал формулу в столбцы B:D, чтобы строка формул поместилась на скриншоте.
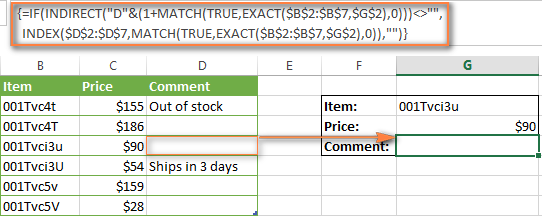
Формула возвращает , если возвращаемая ячейка содержит ноль.
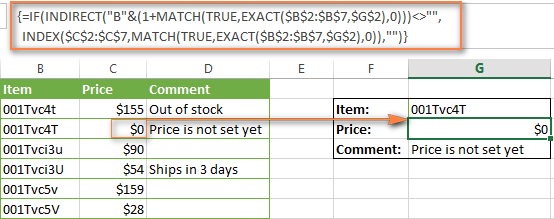
Если Вы хотите, чтобы связка ИНДЕКС и ПОИСКПОЗ отображала какое-то сообщение, когда возвращаемое значение пусто, можете написать его в последних кавычках («») формулы, например, так:
Небольшой тест
Вопрос 1
В зависимости от того, как вы хотели бы назвать переменную, укажите, является ли имя каждой переменной правильным (следует соглашению), неправильным (не соответствует соглашению) или недопустимым (не будет компилироваться) и почему.
Ответ
Правильно.
Ответ
Неправильно – имена переменных не должны начинаться с подчеркивания.
Ответ
Неправильно — имена переменных должны начинаться со строчной буквы.
Ответ
Недопустимо – имена переменных не могут содержать пробелов.
Ответ
Неправильно – имена переменных должны начинаться со строчной буквы.
Ответ
Недопустимо – – это ключевое слово.
Ответ
Правильно.
Ответ
Недопустимо – имена переменных не могут начинаться с цифры.
Ответ
Правильно.
AS WMS: автоматизация склада с адресным хранением с помощью ТСД
Подсистема управления складом AS WMS для конфигураций на платформе 1С 8. AS WMS – готовое решение для эффективного управления адресным складом.
Внедрение системы AS WMS способствует быстрому отбору товара, ускорению инвентаризации, снижению зависимости от персонала, исключению пересорта.
AS WMS встраивается в любую конфигурацию на платформе 1С 8 и работает как единая система без обменов.
В учетной системе нет необходимости менять процессы под AS WMS (например, вводить ордерную схему), AS WMS использует стандартные документы по товародвижению вашей учетной системы.
40000 руб.
10
Tips and More Information
Because most passwords are case sensitive, the letter case you used is one of the first things to look at if your password is said to be wrong when trying to log in to a website. However, since most passwords are hidden behind asterisks, making it impossible to see whether you used the letter casing inappropriately, check that Caps Lock isn’t enabled on your keyboard.
The Windows Command Prompt is case insensitive, meaning you can enter commands like dir as DIR, DiR, dIr, etc.—there really isn’t any reason to do that, but if you happen to have typed it incorrectly, you don’t have to worry about fixing it for the command to work.
The same is true when referring to folder paths from the command line in Windows. For example, cd downloads is the same as cd Downloads and cd DOwnLOADs.



Linux commands, however, are case sensitive. You have to enter them exactly as they appear or you’ll get an error.
Будущее без учета регистра
Регистрозависимость означает, что компьютерные системы различают заглавные и строчные буквы, что может приводить к ошибкам и недоразумениям. Например, если пользователь ищет файл или документ, имя которого начинается с заглавной буквы, а он вводит имя с маленькой буквы, система не сможет найти нужный файл.
Однако, будущее без учета регистра представляет новую эру, где компьютерные системы регистронезависимы и способны распознавать слова независимо от их регистра. Это значит, что пользователи смогут искать файлы, документы и другую информацию, используя любую комбинацию заглавных и строчных букв без ограничений.
Введение регистронезависимости приведет к упрощению и повышению эффективности использования компьютерных систем. Пользователи смогут быстро и легко находить нужную информацию, не тратя время на исправление ошибок, связанных с регистрозависимостью.
Без учета регистра будущее компьютерных систем станет более удобным и интуитивно понятным для пользователей. Это улучшит процесс работы, уменьшит количество ошибок и повысит эффективность использования компьютерной технологии во всех сферах деятельности.
Тенденции развития
Одной из основных тенденций развития без учета регистра является его все большая популярность и использование. С развитием интернета и информационных технологий количество текстовой информации, которую нужно обрабатывать, только увеличивается. Используя без учета регистра, можно значительно упростить и ускорить процесс обработки текста.
Другой тенденцией развития без учета регистра является появление новых алгоритмов и методов обработки текстовой информации. Технологии и исследования в этой области постоянно развиваются, что позволяет создавать более эффективные и точные инструменты для работы с текстом без учета регистра.
Также наблюдается тенденция к расширению области применения без учета регистра. Если раньше он применялся в основном в области поиска информации, то сейчас он активно используется в машинном обучении, обработке естественного языка, анализе данных и других областях.
В целом, можно сказать, что без учета регистра является одним из важных инструментов в обработке и анализе текстовой информации, и его использование будет только увеличиваться в будущем.
Возможные проблемы и решения
Работа без учета регистра может привести к ряду потенциальных проблем, которые следует учитывать при разработке или использовании программного обеспечения.
- Потеря данных: Если при поиске или сопоставлении строк не учитывается регистр, это может привести к потере данных. Например, если в базе данных есть два пользователя с именем «John» и «john», без учета регистра эти имена будут считаться одинаковыми, что может привести к ошибкам при обработке или анализе данных.
- Некорректные результаты: Без учета регистра строки могут быть неправильно отсортированы или сгруппированы. Например, слова «APPLE» и «apple» могут быть рассмотрены как разные слова при поиске или сортировке без учета регистра, что может привести к неправильным результатам.
- Уязвимость безопасности: Игнорирование регистра может создать уязвимости безопасности в системе. Например, если при аутентификации паролей не учитывается регистр, злоумышленник может получить доступ к учетной записи, используя пароль с другим регистром буквы.
Для решения проблем, связанных с работой без учета регистра, рекомендуется следующее:
- Стандартизация данных: Перед обработкой или хранением данных рекомендуется приводить все строки к определенному регистру. Это позволит избежать путаницы и неправильной обработки данных.
- Использование правильных алгоритмов сопоставления строк: При необходимости сравнивать или искать строки без учета регистра, следует использовать соответствующие алгоритмы, которые учитывают регистр символов и обеспечивают правильные результаты.
- Регулярные выражения: Использование регулярных выражений может помочь в обработке строк без учета регистра. Регулярные выражения могут быть использованы для поиска, замены или сопоставления строк с разным регистром символов.
- Обучение пользователей: Если система должна поддерживать работу без учета регистра, рекомендуется провести обучение пользователей, чтобы они были в курсе ограничений и правил использования системы. Это поможет избежать неправильного ввода данных и предотвратить возникновение проблем.
Знаки с учетом регистра в конкретных языках
В различных языках мира существуют знаки, которые имеют разные значения в зависимости от их регистра
Это означает, что важно учитывать регистр при использовании этих знаков, чтобы правильно интерпретировать их смысл
Рассмотрим некоторые языки, где знаки с учетом регистра играют важную роль:
Английский язык
В английском языке знаки с учетом регистра могут изменять значение слова или фразы. Например, слова «Hand» и «hand» имеют разные значения: «Hand» означает «рука», а «hand» может означать «помочь» или «передавать». Также, знаки с учетом регистра используются для обозначения начала предложений и имен собственных.
Немецкий язык
В немецком языке регистр знаков также имеет значение. Например, слово «Mann» с большой буквы означает «мужчина», а «mann» с маленькой буквы означает «человек» в общем смысле. Кроме того, в немецком языке запись имен собственных всегда начинается с заглавной буквы.
Французский язык
Во французском языке регистр также играет важную роль. Например, слова «un» и «Un» имеют разные значения: «un» означает «один», а «Un» может означать «единица» (в математике) или «ООН» (Организация Объединенных Наций). Также, во французском языке имена собственные всегда начинаются с заглавной буквы.
Русский язык
В русском языке регистр знаков не играет такой важной роли, как в вышеперечисленных языках. Однако, иногда регистр знаков может менять значение слова
Например, слова «Писать» и «писать» имеют разные значения: «Писать» означает «написать», а «писать» означает «записывать» или «постоянно писать». Также, в русском языке начало предложения всегда пишется с заглавной буквы.
Важно знать и учитывать знаки с учетом регистра при использовании различных языков, чтобы избежать недоразумений и правильно понимать смысл коммуникации
Важные области
Чувствительность к регистру может отличаться в зависимости от ситуации:
- Поиск : пользователи ожидают, что системы поиска информации будут иметь правильную чувствительность к регистру в зависимости от характера операции. Пользователи, которые ищут слово «собака» в онлайн-журнале, вероятно, не хотят делать различия между «собакой» и «собакой», поскольку это различие в написании; слово должно быть сопоставлено независимо от того, появляется оно в начале предложения или нет. С другой стороны, пользователи, которые ищут информацию о бренде, товарном знаке, человеческом имени или названии города, могут быть заинтересованы в выполнении операции с учетом регистра для фильтрации нерелевантных результатов. Например, кто-то, выполняющий поиск по имени «нефрит», не захотел бы найти упоминания о минерале под названием «нефрит». Например, в английской Википедии поиск по запросу Friendly fire возвращает военную статью, а Friendly Fire (с заглавной буквы «огонь») возвращает страницу значений.
- Имена пользователей : системы аутентификации обычно рассматривают имена пользователей как нечувствительные к регистру, чтобы облегчить запоминание, снизить сложность набора и исключить возможность как ошибки, так и мошенничества, когда два имени пользователя идентичны во всех аспектах, кроме регистра одной из их букв. Однако в этих системах не учитывается регистр. Они сохраняют регистр символов в имени, чтобы пользователи могли выбрать эстетически приятную комбинацию.
- Пароли : Системы аутентификации обычно рассматривают пароли как чувствительные к регистру. Это позволяет пользователям усложнять свои пароли.
- : Традиционно Unix-подобные операционные системы обрабатывают имена файлов с учетом регистра, а Microsoft Windows — без учета регистра, но для большинства файловых систем с сохранением регистра. Подробнее см. Ниже.
- Имена переменных : в некоторых языках программирования для имен переменных учитывается регистр, в других — нет. Для получения дополнительных сведений см. Ниже.
- URL-адреса : разделы пути, запроса, фрагмента и авторитетного URL-адреса могут или не могут быть чувствительными к регистру, в зависимости от принимающего веб-сервера . Однако часть схемы и хоста написана строго в нижнем регистре.
Без учета регистра в различных языках
Понятие «без учета регистра» применяется не только в английском языке, но и в других языках. Оно указывает на то, что при сравнении или поиске символов или слов не учитывается их регистр. Это означает, что заглавные и строчные буквы считаются одинаковыми.
В русском языке также можно сказать, что символы сравниваются без учета регистра. Например, слова «дом» и «ДОМ» будут считаться одинаковыми при поиске или сравнении без учета регистра.
Однако, не все языки имеют понятие «без учета регистра» в таком же смысле, как в английском или русском языке. Некоторые языки, например, турецкий, имеют свои особенности в отношении регистра символов. В турецком языке верхний регистр для некоторых букв имеет свои особые формы, поэтому при сравнении должны учитываться эти особенности.
Таким образом, понятие «без учета регистра» может немного отличаться в различных языках, и применение этого понятия зависит от языковых особенностей и контекста, в котором используется.
Особенности без учета регистра в русском языке
1. Алфавит. Русский алфавит состоит из 33 букв, причем 10 из них – это заглавные (A, Б, В, Г, Д, Е, Ё, Ж, З, И). Следует помнить, что русский язык не применяет строчные заглавные буквы и знаки препинания.
2. Неоднозначность. Без учета регистра в русском языке может возникать неоднозначность и ошибки в понимании текста. Например, слова «Москва» и «москва» могут иметь разные значения (название города и существительное «москва» в общем значении).
3. Семантические оттенки. В русском языке заглавные буквы часто используются для выделения имен собственных и главных слов в предложениях. Без учета регистра можно потерять эти оттенки и значимость слова в контексте.
4. Программирование. В программировании без учета регистра обычно используется для упрощения поиска и сортировки текстовых данных. Но в русском языке это не всегда работает без ошибок, из-за вышеуказанных особенностей.


Иметь понимание о без учета регистра в русском языке очень важно для точного и правильного использования информации. Это поможет избежать ошибок и недоразумений при обработке текстовых данных и общении на письме
Влияние без учета регистра в английском языке
В английском языке отсутствие различия между прописными и строчными буквами может оказывать значительное влияние на смысл выражений и слов.
Когда мы игнорируем регистр, это означает, что мы не различаем между прописными и строчными буквами при чтении или написании текста. Например, слово «apple» (яблоко) и «Apple» (компания Apple) могут быть восприняты как одно и то же слово, если игнорировать регистр.
Это свойство языка может быть использовано при создании паролей или проверке идентичности символов. При сравнении паролей или символов в программировании можно использовать функции, которые игнорируют регистр для более гибкого сравнения, учитывая, что пользователи могут вводить пароль или символы с разным использованием прописных и строчных букв.
Однако, влияние без учета регистра также может создавать сложности при использовании английского языка. Необходимо быть внимательными, чтобы не перепутать два различных значения одного и того же слова из-за игнорирования регистра. Например, слова «read» и «Read» имеют разное значение — «читать» и «Прочитать» соответственно, что является примером влияния без учета регистра.
Таким образом, понимание и учет символов регистра в английском языке играют важную роль в правильном понимании и передаче смысла текста. Игнорирование регистра может привести к неправильному толкованию и восприятию информации.
Как знаки с учетом регистра влияют на юзабилити
Знаки с учетом регистра являются важным аспектом для улучшения юзабилити веб-сайта. Правильное использование знаков с учетом регистра помогает улучшить понимание контента и облегчает навигацию для пользователей.
Существует несколько способов использования знаков с учетом регистра веб-сайта:
Использование заглавных букв в названиях разделов и подразделов.
Выделение важной информации с помощью использования знаков с учетом регистра.
Использование разных шрифтов и размеров букв для обозначения различных типов контента.
Один из примеров использования знаков с учетом регистра — это обозначение заголовков разделов и подразделов. Использование заглавных букв в названиях позволяет читателю легко определить структуру информации и быстро ориентироваться на странице.
Еще одним способом использования знаков с учетом регистра является выделение важных слов и фраз. Чтение текста с использованием выделенных знаков помогает пользователю быстро уловить ключевую информацию и сосредоточиться на наиболее значимых частях текста.
Различные шрифты и размеры букв могут использоваться для создания визуальной иерархии на странице. Например, заголовки могут быть отформатированы шрифтом большего размера и жирным начертанием, что делает их более заметными на странице.
Преимущества использования знаков с учетом регистра
Недостатки использования знаков с учетом регистра
Улучшение понимания контента
Быстрая навигация по странице
Выделение важной информации
Может создать смущение, если использовано неправильно
Требует дополнительных усилий при верстке и оформлении
В заключение, правильное использование знаков с учетом регистра помогает улучшить юзабилити веб-сайта
Использование заглавных букв в названиях разделов и подразделов, выделение важной информации и использование разных шрифтов и размеров букв создает более понятную и удобную среду для пользователей